파이썬 데이터 분석 : 판다스 데이터프레임 통계량, 그래프
바이낸스 비트코인 백테스팅 데이터를 엑셀에 정리했습니다. 이 엑셀 파일을 파이썬 판다스 read_excel() 함수로 불러와서 데이터프레임에 저장하고 난 후부터, 본격적인 파이썬 데이터 분석의 단계로 넘어갈 수 있습니다. 이번 포스팅에서는 엑셀 파일을 읽고, pivot_table()로 변환 후 describe()로 통계량을 분석하고, 이를 pyplot으로 그리는 방법까지 알아보겠습니다.
글의 순서
파이썬 판다스로 엑셀 파일 원하는 부분 골라 읽고, pivot_table()로 데이터 변환
파이썬 데이터 분석 : 판다스 데이터프레임 describe()
파이썬 데이터 분석 : matplotlib.pyplot 그래프
파이썬 코드 : 판다스 통계량과 그래프로 파이썬 데이터 분석
파이썬 판다스로 엑셀 파일 원하는 부분 골라 읽고, pivot_table()로 데이터 변환
지난 포스팅 파이썬 판다스 데이터 분석 : pivot, 엑셀 입력, 출력라는 포스팅에서 엑셀 파일을 파이썬 판다스 데이터프레임으로 읽어온 후 pivot_table() 함수로 변환했었습니다.
pivot_table() 함수로 변환했던 최종 결과물은 바이낸스 비트코인 변동성 돌파전략 백 테스팅 결과라는 포스팅의 결과에서 확인했던 아래 형태의 데이터입니다.
파이썬 데이터 분석 : 판다스 데이터프레임 describe()
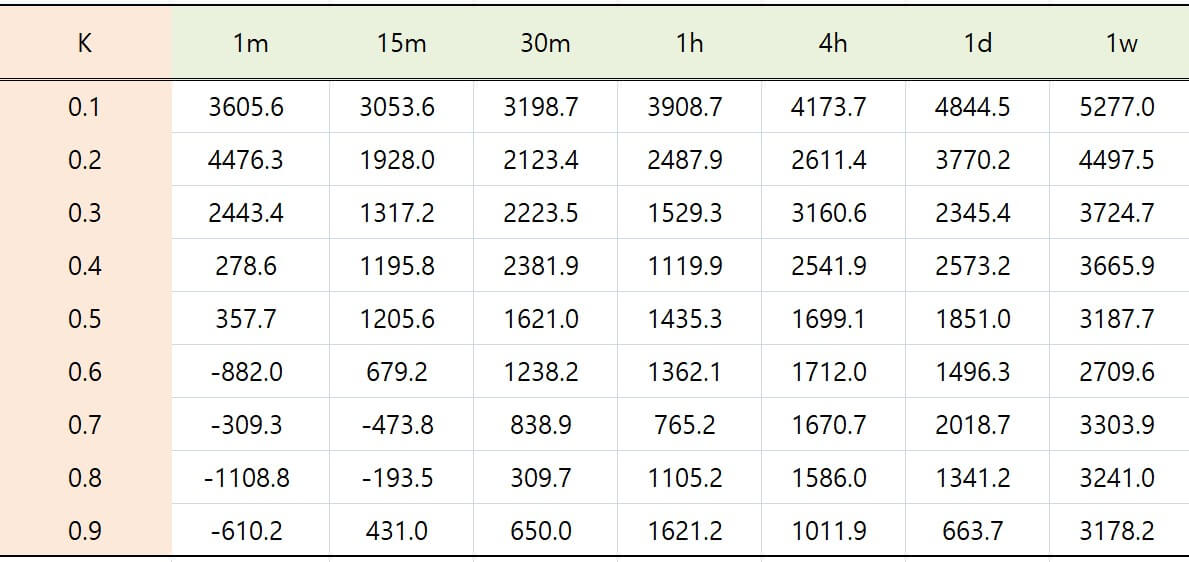
describe() 함수는 판다스 데이터프레임 전체의 요약정보를 보여주는 함수입니다. 정확하게는 요약통계량입니다. describe() 함수는 각 열(column) 별로 count, mean, std, min, 25%, 50%, 75%, max 값을 출력합니다. 각각의 의미는 다음과 같습니다.
▶count : 컬럼별 총 데이터 개수
▶mean/std : 각 컬럼별 데이터의 평균/표준편차
▶min/max : 각 컬럼별 데이터의 최소값/최대값
▶25%/50%/75% : 각 컬럼별 25%, 50%, 75% 위치의 값, 평균을 보완하는 값
describe()를 사용하면 각 시간간격 별, K값 별로 평균과 표준편차를 비교해서 어떤 조합이 제일 좋은지를 알아볼 수 있습니다. 만약 데이터프레임 전체가 아니라 하나의 컬럼, 예를들어1분을 뜻하는 1m의 요약통계량을 보고싶다면, pivot[‘1m’].describe()를 입력하면 됩니다.
두 개 이상의 컬럼에 대한 요약통계량을 보려면 어떻게 해야 할까요? pivot[[‘1m’,’15m’,’1h’]].describe()에서처럼 원하는 컬럼을 리스트 [ ] 로 묶으면 되겠습니다.
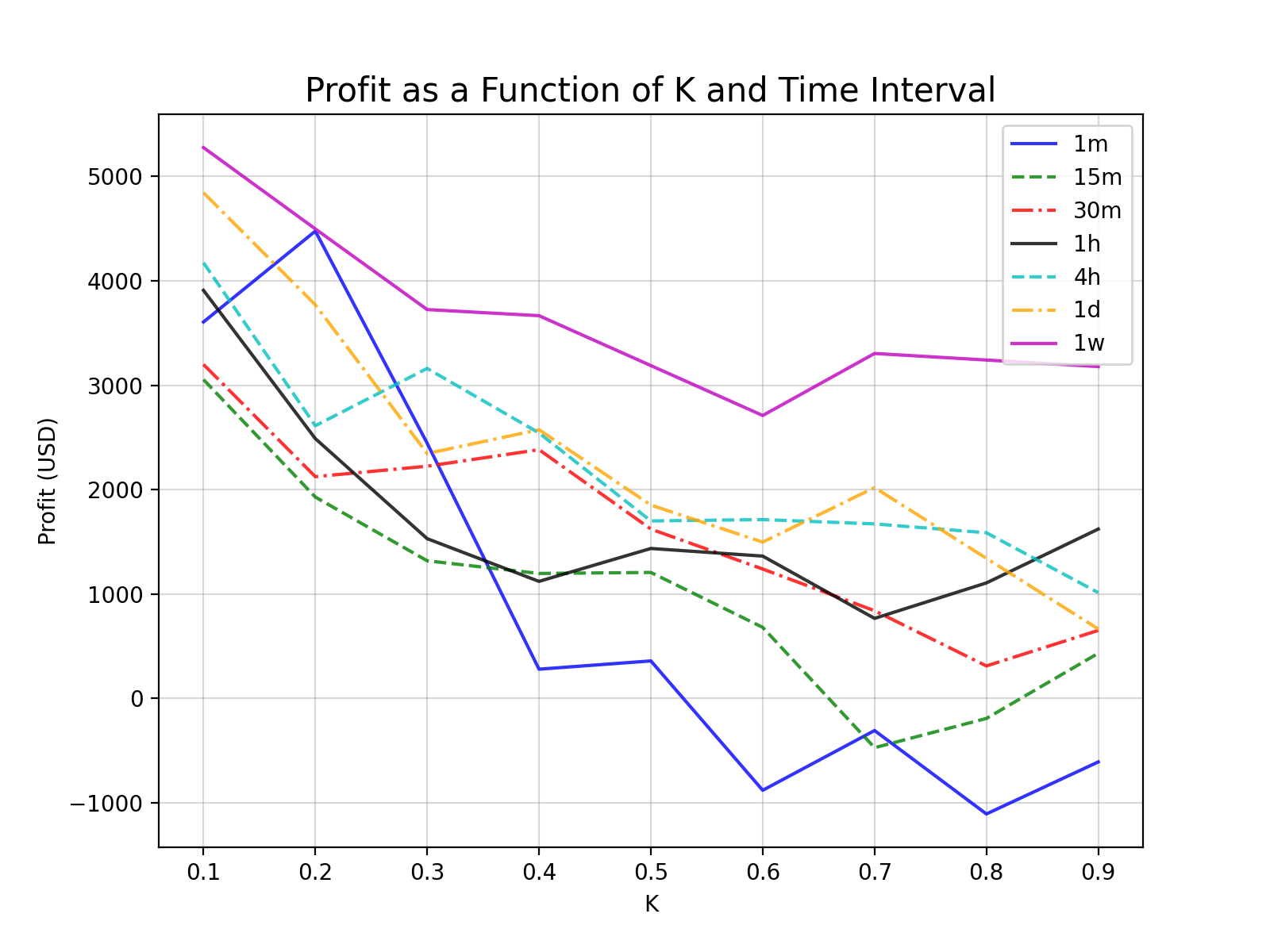
파이썬 데이터 분석 : matplotlib.pyplot 그래프
숫자로 된 데이터는 개수가 많아질수록 의미를 파악하기가 어려워집니다. 이런 데이터를 한눈에 파악하는데 가장 좋은 방법이 그래프이고, 파이썬에서는 그래프를 그리는데 matplotlib라는 패키지가 널리 사용되고 있습니다. 그중에서도 우리가 시각화하고자 하는 데이터에는 pyplot이 가장 알맞은 모듈입니다. 참고로 matplotlib의 pyplot을 이용한 방법은 아래 4개의 포스팅에 정리되어 있습니다.
matplotlib의 pyplot을 이용한 가시화 방법 :
1. 시계열 데이터 가시화 (1) 파이썬 그래프 그리기 3단계
2. 시계열 데이터 가시화 (2) 보고서용 파이썬 그래프 만들기
3. 시계열 데이터 가시화 (3) 파이썬 날짜변환, pandas를 이용한 그래프 그리기
4. 시계열 데이터 가시화 (4) 2개 y축 그래프로 코인 가격 비교
이 포스팅에서는 아래의 방법으로 가시화 하였습니다.
(1) Excel 파일에서 원하는 부분만 불러온 후 Pandas DataFrame에 저장
(2) 판다스 pivot_table 함수를 이용하여 데이터 형태 변환한 후 데이터프레임 변수 pivot에 저장
(3) 데이터프레임 변수 pivot의 열(column) 순서 변경
(4) 판다스 데이터프레임 통계량 확인 : describe()
(5) 데이터 가시화 준비 : matplotlib.pyplot 이용
(5-1) 인덱스 별로 각 열 데이터 가시화
(5-2) 그래프 제목, x, y축 이름 입력
(5-3) 그래프 가독성 향상을 위한 격자, 범례 추가
(6) 데이터 가시화 결과(그래프 출력) 확인 : 화면 출력 또는 파일 출력 중 선택 필요
그래프를 jpeg, png, tiff등 그림 파일로 저장하기 위해서는 savefig() 함수를 사용합니다. 이때 화면에 출력하는 show() 함수와 함께 쓰면 그래프 파일이 제대로 저장되지 않습니다. show() 함수나 savefig() 함수 중 하나를 선택해야 한다는 사실을 기억해 주시기 바랍니다. 또한, savefig() 함수의 파라미터로 넘겨주는 dpi 값은 그림 파일의 선명도를 조절하는 변수이며, 기본값은 100입니다.
파이썬 코드 : 판다스 통계량과 그래프로 파이썬 데이터 분석
판다스 통계량을 계산해주는 describe() 함수와 pyplot 그래프로 파이썬 데이터 분석을 해보았습니다. 실습코드01의 #04, #05 부분을 출력파일로 확인해 보시기 바랍니다. 썸네일은 실습코드로 만든 btc_price.png 파일입니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
import pandas as pd import numpy as np import matplotlib.pyplot as plt #01) Excel 파일에서 원하는 부분만 불러온 후 Pandas DataFrame에 저장 # file_path + file name = 'C:/_python/pandas/btc_price.xlsx' file_path = 'C:/_python/pandas/' df = pd.read_excel(io=file_path +'back_testing_result.xlsx', sheet_name='백테스팅결과', usecols='A:C', skiprows=0, skipfooter=4) #02) 판다스 pivot_table 함수를 이용하여 데이터 형태 변환한 후 데이터프레임 변수 pivot에 저장 pivot = pd.pivot_table(df, values='수익', index=['K'], columns=['시간간격'] ) print('\n', '#02') print(type(pivot)) print(pivot) print(pivot.index) print(pivot.columns) #03) 데이터프레임 변수 pivot의 열(column) 순서 변경 pivot = pivot[['1m', '15m', '30m', '1h', '4h', '1d', '1w']] print('\n', '#03') print(pivot.columns) #04) 판다스 데이터프레임 통계량 : describe() print('\n', '#04-1') print(pivot.describe()) print('\n', '#04-2') print(pivot['1m'].describe()) print('\n', '#04-3') print(pivot[['1m','15m','1h']].describe()) #05) 데이터 가시화 준비 #5-1) pyplot으로 가시화하는 판다스 데이터프레임 데이터 fig, ax1 = plt.subplots(nrows=1, ncols=1, figsize=(8,6)) ax1.plot(pivot['1m'], color='b', label='1m', alpha=0.8, linestyle='solid') ax1.plot(pivot['15m'], color='g', label='15m', alpha=0.8, linestyle='dashed') ax1.plot(pivot['30m'], color='r', label='30m', alpha=0.8, linestyle='dashdot') ax1.plot(pivot['1h'], color='k', label='1h', alpha=0.8, linestyle='solid') ax1.plot(pivot['4h'], color='c', label='4h', alpha=0.8, linestyle='dashed') ax1.plot(pivot['1d'], color='orange', label='1d', alpha=0.8, linestyle='dashdot') ax1.plot(pivot['1w'], color='m', label='1w', alpha=0.8, linestyle='solid') #5-2) 그래프 제목, x, y축 이름 ax1.set_title('Profit as a Function of K and Time Interval', size=15) ax1.set_xlabel('K') ax1.set_ylabel('Profit (USD)') #5-3) 그래프 가독성 향상 : 격자 추가, legend 추가 ax1.grid(axis='x', which='major', color='gray', alpha=0.3) ax1.grid(axis='y', which='major', color='gray', alpha=0.3) ax1.legend(loc='upper right') #6) 데이터 가시화 결과(그래프 출력) 확인 : 화면 출력 또는 파일 출력 중 선택 필요 print('\n', '#06 :: 화면출력 또는 파일출력 중 선택해야 합니다.') #6-1) 화면에 출력 plt.show() #6-2) 파일로 출력 # plt.savefig(file_path +'btc_price.png', dpi=200) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
#02 <class 'pandas.core.frame.DataFrame'> 시간간격 15m 1d 1h 1m 1w 30m 4h K 0.1 3053.64599 4844.4599 3908.72000 3605.5980 5276.99199 3198.67390 4173.67899 0.2 1927.95390 3770.1699 2487.91399 4476.2660 4497.53300 2123.42999 2611.38990 0.3 1317.21890 2345.3650 1529.26500 2443.4220 3724.67590 2223.53000 3160.59190 0.4 1195.83900 2573.1800 1119.90990 278.5700 3665.90799 2381.90399 2541.85590 0.5 1205.58490 1850.9899 1435.26490 357.7400 3187.74499 1620.96000 1699.06490 0.6 679.19790 1496.3499 1362.11800 -881.9690 2709.58190 1238.20590 1711.95199 0.7 -473.79390 2018.7100 765.16190 -309.3059 3303.86699 838.91990 1670.67600 0.8 -193.54000 1341.1939 1105.15400 -1108.7859 3241.03790 309.71400 1585.95999 0.9 430.95290 663.6769 1621.23200 -610.2040 3178.20800 650.04899 1011.91200 Float64Index([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9], dtype='float64', name='K') Index(['15m', '1d', '1h', '1m', '1w', '30m', '4h'], dtype='object', name='시간간격') #03 Index(['1m', '15m', '30m', '1h', '4h', '1d', '1w'], dtype='object', name='시간간격') #04-1 시간간격 1m 15m 30m 1h 4h 1d 1w count 9.000000 9.00000 9.000000 9.000000 9.000000 9.000000 9.000000 mean 916.814578 1015.89551 1620.598519 1703.859966 2240.786841 2322.677267 3642.838740 std 2065.294721 1077.08327 942.331159 954.135127 977.700716 1286.039596 788.867445 min -1108.785900 -473.79390 309.714000 765.161900 1011.912000 663.676900 2709.581900 25% -610.204000 430.95290 838.919900 1119.909900 1670.676000 1496.349900 3187.744990 50% 278.570000 1195.83900 1620.960000 1435.264900 1711.951990 2018.710000 3303.866990 75% 2443.422000 1317.21890 2223.530000 1621.232000 2611.389900 2573.180000 3724.675900 max 4476.266000 3053.64599 3198.673900 3908.720000 4173.678990 4844.459900 5276.991990 #04-2 count 9.000000 mean 916.814578 std 2065.294721 min -1108.785900 25% -610.204000 50% 278.570000 75% 2443.422000 max 4476.266000 Name: 1m, dtype: float64 #04-3 시간간격 1m 15m 1h count 9.000000 9.00000 9.000000 mean 916.814578 1015.89551 1703.859966 std 2065.294721 1077.08327 954.135127 min -1108.785900 -473.79390 765.161900 25% -610.204000 430.95290 1119.909900 50% 278.570000 1195.83900 1435.264900 75% 2443.422000 1317.21890 1621.232000 max 4476.266000 3053.64599 3908.720000 #06 :: 화면출력 또는 파일출력 중 선택해야 합니다. |
마치며 …
바이낸스 비트코인 백테스팅 데이터가 저정된 엑셒 파일을 파이썬 판다스 read_excel() 함수로 불러와서 데이터프레임에 저장하고 난 후부터, 본격적인 데이터 분석의 단계로 넘어갈 수 있습니다. 이번 포스팅에서는 엑셀 파일을 읽고, pivot_table()로 변환 후 describe()로 통계량을 분석하고, 이를 pyplot으로 그리는 방법까지 알아보았습니다.
함께 참고하면 더 좋은 글 :
1. 바이낸스 코인거래소 API Key로 계좌에 접속하는 파이썬 프로그래밍
2. 파이썬 바이낸스 API로 시계열 데이터를 가져오는 파이썬 프로그래밍
3. 파이썬 판다스 데이터 분석 : pivot, 엑셀 입력, 출력
4. 파이썬 바이낸스 API 시계열 데이터분석. 판다스 시간 처리
5. 바이낸스 비트코인 투자 백 테스팅. 파이썬 코인 투자 연습
6. 바이낸스 비트코인 변동성 돌파전략 백 테스팅 결과
7. 파이썬 프로그래밍 시작
참고자료
Python Tutorial Read Excel with Python Pandas