
파이썬 판다스로 엑셀 파일의 원하는 부분 추출 방법
파이썬 판다스는 엑셀 파일을 불러와서 데이터프레임에 저장한 후, 연산과 데이터 추출, 데이터 가시화 등의 작업을 할 수 있습니다. 물론 엑셀에서도 이런 작업을 모두 할 수 있지만, 데이터를 자동으로 처리하는 데는 판다스가 유리합니다. 이 포스팅에서는 파이썬 판다스로 엑셀 파일에서 원하는 부분을 추출해오는 방법을 알아보겠습니다.
글의 순서
판다스 (pandas) : 시리즈 vs. 데이터 프레임
엑셀 파일 입력 : 파이썬 판다스 데이터프레임 함수 read_excel()
엑셀 파일을 파이썬 판다스 데이터프레임으로 만드는 파라미터
파이썬 엑셀 파일 입력 : 원하는 데이터만 추출하기
판다스 (pandas) : 시리즈 vs. 데이터 프레임
파이썬 라이브러리인 판다스로는 다양한 자료형을 갖는 데이터를 한꺼번에 수정하거나 재배치 할 수 있고, 연산까지도 가능합니다. 판다스에서는 데이터의 배열을 시리즈(series) 또는 데이터프레임(DataFrame)이라고 부릅니다. 시리즈는 1차원 형태이고, 데이터프레임은 2차원 형태입니다. 시리즈를 합쳐 놓은 것을 데이터프레임이라고 할 수 있습니다. 시리즈와 데이터프레임을 비교해보면 아래와 같습니다.
▶pandas Series : index와 값으로 구성
▶pandas DataFrame : index, column과 값으로 구성
(1) 판다스 시리즈 (series)
1차원 배열 형태를 다루는 Series는 2열의 표를 만드는데, 이 표에서 1열은 인덱스(index), 2열은 값(values)을 의미합니다. 판다스에서는 인덱스를 설정할 때 정수뿐만 아니라 실수, 문자 등 다양한 데이터 형태로 설정 할 수 있습니다.
(2) 판다스 데이터프레임 (DataFrame)
2차원 형태의 표가 데이터프레임입니다. 엑셀 화면에서 볼 수 있는 그 표 형태가 바로 데이터 프레임입니다. 엑셀 화면을 보면 행을 표시하는 부분은 숫자로, 열을 표시하는 부분은 알파벳으로 되어 있습니다. 엑셀의 숫자와 판다스 데이터프레임을 1:1로 대응시킬 수 있는데, 숫자가 인덱스, 알파벳이 컬럼 이름과 대응됩니다.
판다스 데이터프레임은 여러 개의 시리즈를 합쳐서 나타낸 것으로, 데이터분석과 머신러닝에서 데이터를 다루는데 핵심적인 역할을 합니다. 데이터프레임을 생성하는 데는 DataFrame() 함수를 이용합니다.
엑셀 파일 입력 : 파이썬 판다스 데이터프레임 함수 read_excel()
판다스에서 엑셀 파일의 sheet를 불러 올 수 있습니다. 이떼 pandas의 read_excel() 함수를 사용합니다. 엑셀도 데이터 분석에 유용한 프로그램인데, 파이썬 판다스에 접목된다면 시너지 효과를 얻을 수 있을 것입니다.
실습코드01은 파이썬으로 엑셀파일을 불러와서 판다스 데이터프레임 변수 df에 저장하는 코드입니다. pd.read_excel()이 pandas의 read_excel() 함수를 나타내는 것입니다. 함수의 파라미터로는 파일이 있는 위치의 절대 경로를 사용한 경우입니다. 아래의 그림이 파이썬으로 불러오고자 하는 엑셀파일입니다.
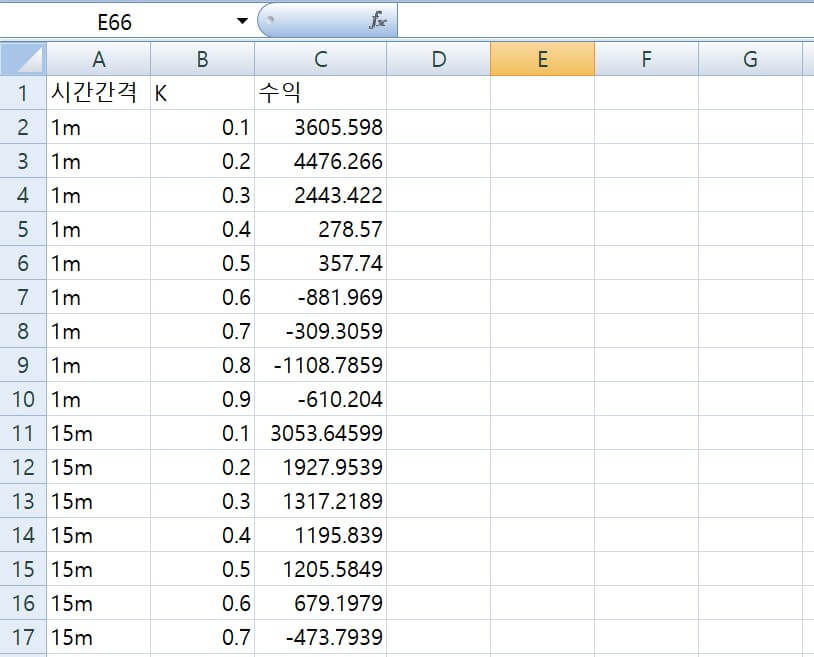
|
1 2 3 4 5 |
import pandas as pd #01) Excel 파일 불러온 후 Pandas DataFrame에 저장 df = pd.read_excel('C:/_python/pandas/btc_price.xlsx') print(df.head()) |
|
1 2 3 4 5 6 |
시간간격 K 수익 0 1m 0.1 3605.598 1 1m 0.2 4476.266 2 1m 0.3 2443.422 3 1m 0.4 278.570 4 1m 0.5 357.740 |
엑셀 파일을 파이썬 판다스 데이터프레임으로 만드는 파라미터
pandas의 read_excel() 함수로 엑셀파일을 불러올 때 사용할 수 있는 파라미터가 실습코드 보다는 많은데 사용빈도가 높은 파라미터를 정리해 보겠습니다.
▶ io
엑셀 파일이 있는 경로. 만약 웹 상에 있다면 url을 지정합니다.
여기서, url은 웹 주소를 의미합니다.
▶ sheet_name=
엑셀 파일 안에 여러개의 sheet가 있을 경우, sheet 이름을 지정해서 불러올 수 있습니다. 이 파라미터를 넘겨주지 않으면 엑셀파일 안에 활성화 되어 있는 sheet를 불러옵니다.
▶ header
열 이름으로 사용할 행을 지정합니다. 별도 지정하지 않으면 첫 행을 열 이름으로 지정합니다.
▶ names
열 이름을 리스트 형태로 지정할 수 있습니다.
▶index_col
index로 사용할 열의 이름 또는 열의 번호를 지정합니다. 만약 지정해주지 않으면 0부터 시작하는 행 번호가 첫 번째 열에 추가됩니다.
▶ usecols = “ ”
엑셀 파일에서 읽어올 데이터의 열을 선택할 수 있습니다. 만약 지정해주지 않는다면 전체 열이 선택됩니다. 엑셀에서 선택하고 싶은 열이 B, D, F, G, H 열이라면 usecols=[B, D, F:H] 처럼 리스트 형태로 정해줄 수 있습니다. F:H는 F부터 H까지라는 의미입니다.
▶ skiprows
가져오고 싶지 않은 행을 지정해 줄 수 있습니다. 리스트 형태로 지정할 수도 있고, 숫자를 써서 맨 위에서부터 몇 행을 날릴 것인지 지정할 수 있습니다. skiprows = [1, 2] 라고 지정했다면, 2행과 3행을 건너뛰고 가져옵니다. skiprows = 1이라고 그냥 숫자를 쓴다면 첫 1행을 날린 후 2행부터 가져옵니다.
▶ skipfooter
만약 skipfooter = 3이라고 지정했다면 마지막 3행을 가져오지 않습니다.
파이썬 엑셀 파일 입력 : 원하는 데이터만 추출하기
아래 그림은 엑셀파일의 ‘백테스팅결과_post’라는 sheet를 보여주고 있습니다. 이 중에서 판다스 데이터프레임으로 만들고 싶은 부분은 전체 16행 중 2행부터 11행, I열까지 중 B열부터 I열 까지입니다.
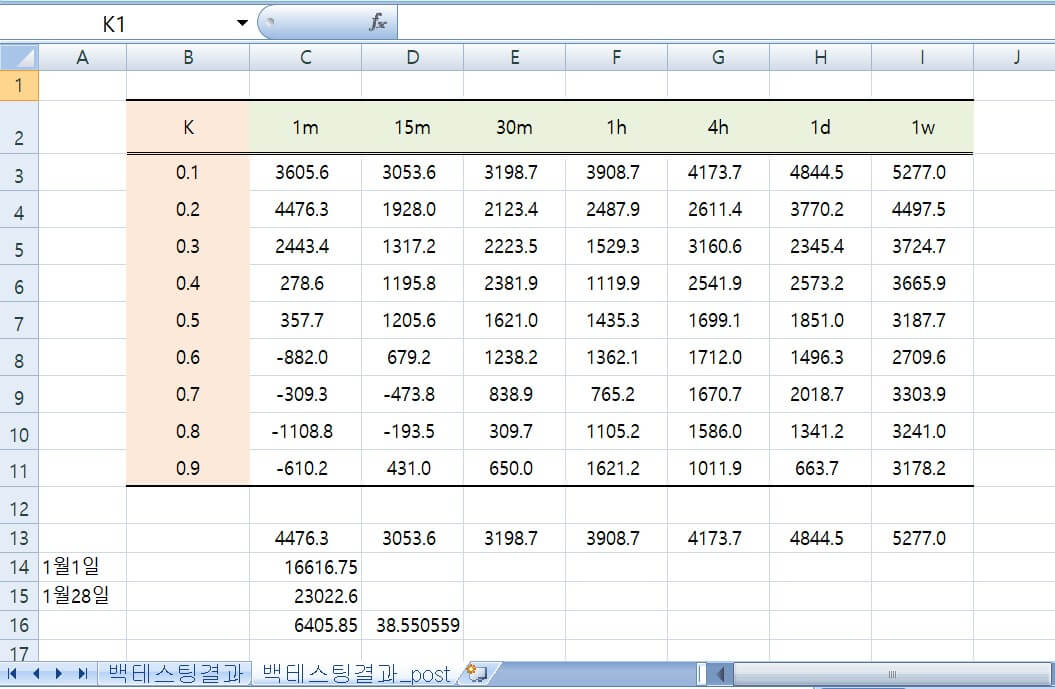
이 부분만 추출해내기 위한 read_excel()의 파라미터를 실습코드02에 나타내었습니다. 판다스 데이터프레임 변수인 df에 저장 한 후 출력한 결과를 보면, 꼭 필요한 부분만 저장이 되었다는 것을 확인할 수 있습니다. index_col을 첫 번째 열을 의미하는 0으로 설정하여 B열이 인덱스로 저장되었습니다.
|
1 2 3 4 5 6 7 8 9 10 |
import pandas as pd #01) Excel 파일에서 원하는 부분만 불러온 후 Pandas DataFrame에 저장 df = pd.read_excel(io='C:/_python/pandas/btc_price.xlsx', sheet_name='백테스팅결과_post', usecols='B:I', index_col = 0, skiprows=1, skipfooter=5) print(df) |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#01 1m 15m 30m 1h 4h 1d 1w K 0.1 3605.5980 3053.64599 3198.67390 3908.72000 4173.67899 4844.4599 5276.99199 0.2 4476.2660 1927.95390 2123.42999 2487.91399 2611.38990 3770.1699 4497.53300 0.3 2443.4220 1317.21890 2223.53000 1529.26500 3160.59190 2345.3650 3724.67590 0.4 278.5700 1195.83900 2381.90399 1119.90990 2541.85590 2573.1800 3665.90799 0.5 357.7400 1205.58490 1620.96000 1435.26490 1699.06490 1850.9899 3187.74499 0.6 -881.9690 679.19790 1238.20590 1362.11800 1711.95199 1496.3499 2709.58190 0.7 -309.3059 -473.79390 838.91990 765.16190 1670.67600 2018.7100 3303.86699 0.8 -1108.7859 -193.54000 309.71400 1105.15400 1585.95999 1341.1939 3241.03790 0.9 -610.2040 430.95290 650.04899 1621.23200 1011.91200 663.6769 3178.20800 |
마치며 …
이 포스팅에서는 파이썬 판다스로 엑셀 파일에서 원하는 부분을 추출해오는 방법을 알아보았습니다. 판다스의 read_excel()이라는 함수와 이 함수의 파라미터를 활용하면 엑셀파일의 원하는 sheet에서 원하는 부분의 데이터만 추출할 수 있습니다. 실습코드02로 익숙해질 수 있으리라 기대합니다.
파이썬 판다스는 엑셀 파일을 불러와서 데이터프레임에 저장한 후, 연산과 데이터 추출, 데이터 가시화 등의 작업을 할 수 있습니다. 물론 엑셀에서도 이런 작업을 모두 할 수 있지만, 자동화라는 관점에서는 아무래도 파이썬 프로그래밍이 유리합니다. 다음 포스팅에서는 이렇게 불러온 데이터를 판다스 데이터프레임을 이용하여 분석해보겠습니다.
함께 참고하면 더 좋은 글 :
▶ 파이썬 판다스로 텍스트 파일 읽기 : read_table()
▶ 시계열 데이터 전처리 결과 확인 : pandas Series
▶ 시계열 데이터 전처리 결과 확인 : pandas DataFrame
▶ 파이썬 데이터 분석! 데이터 분석을 위한 코딩언어 파이썬
▶ 시계열 데이터 분석 : pandas CSV 파일 저장, 읽기
▶ 파이썬 바이낸스 API 시계열 데이터분석. 판다스 시간 처리
▶ 바이낸스 비트코인 투자 백 테스팅. 파이썬 코인 투자 연습
▶ 파이썬 판다스 데이터 분석 : pivot, 엑셀 입력, 출력
참고자료
Python Tutorial Read Excel with Python Pandas