파이썬 지도 데이터 가시화 : geopandas
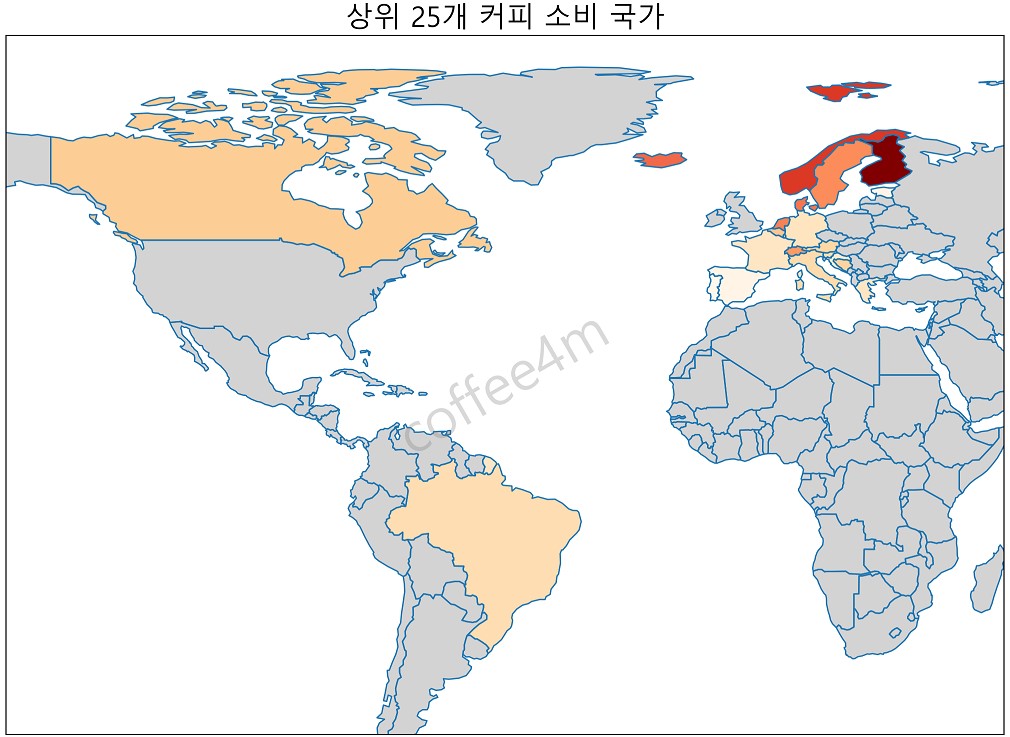
세계지도 위에 상위 25개의 커피 소비 국가를 표시하면, 한 눈에 비교할 수 있습니다. 이번 포스팅에서는 파이썬 지도 데이터 시각화 방법을 알아보겠습니다. geopandas라는 파이썬 패키지를 사용하는 이유와 파이썬 코드를 확인해 보시기 바랍니다.
글의 순서
파이썬 지도 데이터 시각화 패키지 비교
geopandas를 이용한 지도 데이터 시각화 방법
geopandas에 활용할 지도 데이터 다운로드
판다스 데이터프레임 합치기
지도 가시화
파이썬 코드 : 지도 데이터 시각화
파이썬 지도 데이터 가시화 패키지 비교
지도 가시화를 위한 파이썬 패키지를 사용하면 파이썬 코드 몇줄 만으로 쉽게 지도 데이터 가시화가 가능합니다. 일단 우리가 활용할 수 있는 파이썬 지도 가시화 패키지의 장단점을 아래와 같이 비교해 보았습니다.
(1) geopandas
▶장점: 지리 데이터 처리가 매우 쉽고 직관적입니다. 다양한 파일 포맷 지원 (예: Shapefile, GeoJSON 등).
▶단점: 복잡한 지도 가시화나 대규모 데이터를 처리할 때 성능이 떨어질 수 있습니다.
(2) folium
▶장점: 대화형 지도를 만들기 매우 좋습니다. 지도 위에 마커, 경로 등을 쉽게 추가할 수 있습니다.
▶단점: 정적인 지도 이미지 생성에는 적합하지 않습니다.
(3) plotly
▶장점: 대화형 가시화에 강점이 있습니다. plotly를 사용하면 지도를 줌 인/아웃 하거나 데이터 포인트에 대한 세부 정보를 인터랙티브하게 볼 수 있습니다.
▶단점: 초기 설정이 다소 복잡할 수 있습니다.
(4) matplotlib + basemap
▶장점: matplotlib의 모든 기능을 사용할 수 있어, 매우 커스터마이즈된 지도를 만들 수 있습니다.
▶단점: basemap 설치 및 설정이 다소 까다로울 수 있으며, 복잡한 작업에는 부적합할 수 있습니다.
이 중에서 상위 25개국의 커피 소비량 데이터를 가시화하기 위해서 geopandas를 선택했습니다. 무엇보다도 geopandas는 데이터를 지도 위에 간편하게 표현할 수 있기 때문에, 전 세계 데이터를 국가별로 비교하는 용도로는 가장 적합하다고 할 수 있습니다.
geopandas를 이용한 지도 데이터 가시화 방법
세계 상위 25개 국가의 커피 소비량을 색상으로 구분하여 세계 지도 위에 가시화하는 것이 이 포스팅의 목적입니다. 여기서는 geopandas를 이용합니다. geopandas 패키지가 대화형은 아니지만 직관적이고 사용하기 쉽다는 큰 장점이 있습니다. 혹시 대화형 지도가 필요하다면 folium이나 plotly 같은 패키지를 활용해야 합니다.
파이썬 패키지 설치부터 지도 데이터 가시화를 위한 절차를 정리해보면 다음과 같습니다.
(1) 파이썬 패키지 설치 : geopandas, matplotlib, pandas 등
(2) 커피 소비량 데이터 준비 : 판다스 데이터프레임 변수로 데이터 저장
(3) 세계지도 데이터 불러오기 : geopandas 패키지 활용
(4) 커피 소비량 데이터와 지도 데이터를 합침
(5) matplotlib를 이용한 시각화
파이썬 패키지는 pip install geopandas로 설치할 수 있습니다.
geopandas에 활용할 지도 데이터 다운로드
Natural Earth 데이터를 다운로드합니다. 아래의 참고자료에 다운로드 사이트를 링크하겠습니다. 먼저, Natural Earth 웹사이트에서 저해상도 행정 경계 데이터를 다운로드합니다. “Admin 0 – Countries” 데이터만 다운로드 해도 됩니다만, 전체 지도 데이터의 용량이 크지 않으므로 그냥 zip 파일 모두를 다운로드 하시면 되겠습니다.
zip 파일을 압축 해제한 후 .shp 파일을 geopandas를 사용하여 아래처럼 불러옵니다.
|
1 2 3 4 5 |
# 압축 해제된 .shp 파일 경로를 입력하세요. shapefile_path = "path_to_your_shapefile/ne_110m_admin_0_countries.shp" # 세계 지도 데이터 불러오기 world = gpd.read_file(shapefile_path) |
판다스 데이터프레임 합치기
팓다스 데이터프레임 merge 연산을 통해 지도 데이터에 커피 소비량 데이터를 아래와 같이 합칩니다. ADMIN에 지도 데이터의 각 나라 위치 정보가 담겨 있으며, 커피 소비량 데이터가 Country에 들어 있습니다.
|
1 2 |
# 데이터 병합 world = world.merge(df, how='left', left_on='ADMIN', right_on='Country') |
geopandas에서 제공하는 shapefile의 열 중, ADMIN과 SOVEREIGNT에 국가 정보가 들어있습니다. 아래의 코드의 print 문을 이용하여 이를 확인할 수 있습니다. world[[‘ADMIN’, ‘SOVEREIGNT’]].head()를 출력하여 ADMIN 및 SOVEREIGNT 열의 데이터를 확인할 수 있습니다.
ADMIN 열은 일반적으로 지도에 표시될 국가나 지역의 이름을 의미하며, SOVEREIGNT 열은 해당 지역 주권을 가진 국가의 이름을 의미합니다.
지도 데이터 가시화
커피 소비량은 각 국가마다 다른데, 많이 소비하는 국가를 더 진한색으로 표시하는 것이 목표입니다. 소비량에 색상을 대응시킨 후 이를 막대에 표시해 두는데, 여기서는 지도 아래에 가로로 배치되게 하였습니다.
아래 실습코드의 각 행마다 어떤 의미가 있는지 자세히 설명하면 다음과 같습니다.
|
1 |
fig, ax = plt.subplots(1, 1, figsize=(16, 12), subplot_kw={'projection': ccrs.PlateCarree()}) |
▶plt.subplots 함수를 사용하여 하나의 행과 하나의 열로 이루어진 서브플롯을 만듭니다.
▶figsize=(16, 12)는 생성된 그림의 크기를 설정합니다. 폭은 16인치, 높이는 12인치로 설정합니다.
▶subplot_kw={‘projection’: ccrs.PlateCarree()}는 서브플롯의 투영법을 PlateCarree로 설정합니다. PlateCarree는 가장 단순한 경도와 위도 투영법입니다.
|
1 2 |
# 커피 소비량 데이터가 있는 국가를 색으로 표시 world.boundary.plot(ax=ax, transform=ccrs.PlateCarree()) |
▶world.boundary.plot 함수를 사용하여 국가 경계선을 그립니다.
▶ax=ax는 이 경계선을 그릴 축을 지정합니다.
▶transform=ccrs.PlateCarree()는 경계선을 PlateCarree 투영법으로 변환하여 그립니다.
|
1 2 |
world.plot(column='Coffee Consumption (lbs Per Person Per Year)', ax=ax, legend=False, cmap='OrRd', missing_kwds={'color': 'lightgrey'}, transform=ccrs.PlateCarree()) |
▶world.plot 함수를 사용하여 국가별로 커피 소비량 데이터를 색으로 표시합니다.
column=’Coffee Consumption (lbs Per Person Per Year)’는 시각화에 사용할 데이터 열을 지정합니다.
▶ax=ax는 이 그래프를 그릴 축을 지정합니다.
▶legend=False는 범례를 표시하지 않도록 설정합니다.
▶cmap=’OrRd’는 색상 맵을 OrRd(주황색-빨간색)으로 설정합니다.
▶missing_kwds={‘color’: ‘lightgrey’}는 데이터가 없는 지역을 밝은 회색으로 표시합니다.
▶transform=ccrs.PlateCarree()는 이 데이터를 PlateCarree 투영법으로 변환하여 그립니다.
|
1 2 |
# 색상 막대 그래프 설정 sm = plt.cm.ScalarMappable(cmap='OrRd', norm=plt.Normalize(vmin=world['Coffee Consumption (lbs Per Person Per Year)'].min(), vmax=world['Coffee Consumption (lbs Per Person Per Year)'].max())) |
▶plt.cm.ScalarMappable 객체를 사용하여 색상 막대를 설정합니다.
▶cmap=’OrRd’는 색상 맵을 오렌지-레드(OrRd)로 설정합니다.
▶norm=plt.Normalize(vmin=world[‘Coffee Consumption (lbs Per Person Per Year)’].min(), vmax=world[‘Coffee Consumption (lbs Per Person Per Year)’].max())는 데이터 값의 최소값과 최대값을 사용하여 정규화합니다.
|
1 |
sm._A = [] |
▶색상 막대의 배열을 비웁니다. 이는 색상 막대의 값 설정을 위해 필요합니다.
|
1 |
cbar = fig.colorbar(sm, orientation='horizontal', pad=0.05) |
▶fig.colorbar 함수를 사용하여 fig에 색상 막대를 추가합니다.
▶orientation=’horizontal’은 색상 막대의 방향을 가로로 설정합니다.
▶pad=0.05는 색상 막대와 플롯 사이의 간격을 설정합니다.
|
1 2 |
ax.xaxis.set_major_formatter(LongitudeFormatter()) ax.yaxis.set_major_formatter(LatitudeFormatter()) |
위도, 경도 축의 포맷터를 설정하여 위도, 경도 값을 읽기 쉽게 합니다.
파이썬 코드 : 지도 데이터 가시화
지금까지의 과정 모두를 아래의 파이썬 코드에 나타내었습니다. 이 코드를 실행시키면 다음과 같이 지도에 커피소비량이 많은 25개의 국가가 커피 소비량에 맞춰 구분됩니다. 북유럽 국가들에서 커피 소비량이 많다는 사실을 한 눈에 알 수 있습니다.
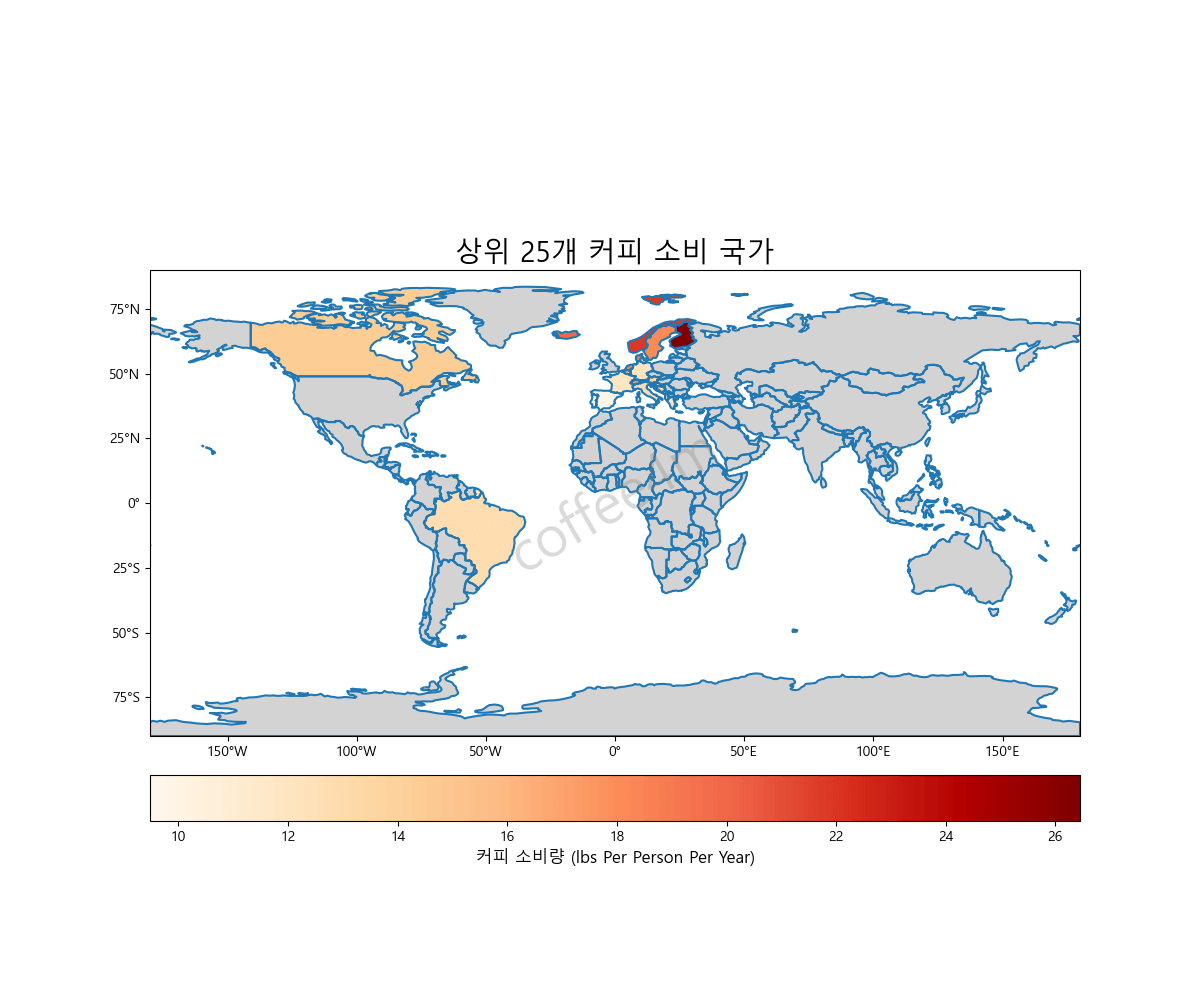
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 |
import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt from matplotlib import font_manager, rc from cartopy import crs as ccrs from cartopy.mpl.ticker import LongitudeFormatter, LatitudeFormatter file_path = 'C:/_python/' file_name = 'top25_coffee_consumption.png' # 한글 폰트 설정 font_path = "C:/Windows/Fonts/malgun.TTF" font = font_manager.FontProperties(fname=font_path).get_name() rc('font', family=font) data = { 'Country': [ 'Finland', 'Norway', 'Iceland', 'Denmark', 'Netherlands', 'Sweden', 'Switzerland', 'Belgium', 'Luxembourg', 'Canada', 'Bosnia and Herzegovina', 'Austria', 'Italy', 'Brazil', 'Slovenia', 'Germany', 'Greece', 'France', 'Croatia', 'Cyprus', 'Lebanon', 'Estonia', 'Spain', 'Portugal', 'United States' ], 'Coffee Consumption (lbs Per Person Per Year)': [ 26.45, 21.82, 19.84, 19.18, 18.52, 18, 17.42, 15, 14.33, 14.33, 13.67, 13.45, 13, 12.79, 12.79, 12.13, 11.9, 11.9, 11.24, 10.8, 10.58, 9.92, 9.92, 9.48, 9.26 ] } df = pd.DataFrame(data) # 세계 지도 데이터 불러오기 file_map_path = 'C:/_python/' shapefile_path = file_map_path + "ne_110m_admin_0_countries.shp" # 세계 지도 데이터 불러오기 world = gpd.read_file(shapefile_path) # Shapefile의 일부 데이터 확인 print(world.head()) print(world.columns) print(world[['ADMIN', 'SOVEREIGNT']].head()) # 데이터 병합 world = world.merge(df, how='left', left_on='ADMIN', right_on='Country') # 지도 시각화 fig, ax = plt.subplots(1, 1, figsize=(12, 10), subplot_kw={'projection': ccrs.PlateCarree()}) # 커피 소비량 데이터가 있는 국가를 색으로 표시 world.boundary.plot(ax=ax, transform=ccrs.PlateCarree()) world.plot(column='Coffee Consumption (lbs Per Person Per Year)', ax=ax, legend=False, cmap='OrRd', missing_kwds={'color': 'lightgrey'}, transform=ccrs.PlateCarree()) # 색상 막대 그래프 설정 sm = plt.cm.ScalarMappable(cmap='OrRd', norm=plt.Normalize(vmin=world['Coffee Consumption (lbs Per Person Per Year)'].min(), vmax=world['Coffee Consumption (lbs Per Person Per Year)'].max())) sm._A = [] cbar = fig.colorbar(sm, orientation='horizontal', pad=0.05) cbar.set_label('커피 소비량 (lbs Per Person Per Year)', size=12) # 제목 추가 ax.set_title('상위 25개 커피 소비 국가', fontdict={'fontsize': 20}, loc='center') # 경도와 위도 축의 레이블 설정 ax.set_xticks([-150, -100, -50, 0, 50, 100, 150], crs=ccrs.PlateCarree()) ax.set_yticks([-75, -50, -25, 0, 25, 50, 75], crs=ccrs.PlateCarree()) ax.xaxis.set_major_formatter(LongitudeFormatter()) ax.yaxis.set_major_formatter(LatitudeFormatter()) # 그래프 출력 plt.savefig(file_path + file_name, dpi=100) plt.show() |
마치며 …
세계지도 위에 상위 25개의 커피 소비 국가를 표시하면, 한 눈에 비교할 수 있습니다. 이번 포스팅에서는 파이썬 지도 데이터 시각화 방법을 알아보았습니다. 전 세계 데이터를 국가별로 비교하는 용도로는 가장 적합한 geopandas라는 파이썬 패키지를 사용하였습니다. 이 포스팅에서의 파이썬 코드를 기반으로 다양한 지도 데이터 가시화를 시도해 보시기 바랍니다.
함께 참고하면 좋은 글
▶ 파이썬 데이터 시각화 : z=f(x,y), 서피스 플롯, 컨투어 플롯
▶ 파이썬 데이터 시각화 : 막대 그래프 작성 2가지 방법(maplotlib.pyplot 활용)
▶ 파이썬 데이터 분석 : 판다스 데이터프레임 통계량, 그래프
▶ 시계열 데이터 분석 : 추세분석 지표 6가지
참고자료
▶ Madhavi Venkatesan(2021), Social and Sustainability Marketing and the Sharing Economy in the Coffee Shop Culture, Social and Sustainability Marketing, pp.839-862, DOI:10.4324/9781003188186-34
▶ Natural Earth, 1:110m Cultural Vectors