OpenAI o3, AI의 한계를 뛰어넘다: 벤치마크 테스트 분석
OpenAI의 새로운 모델 o3는 여러 종류의 벤치마크 테스트를 통해 AI의 한계가 계속 확장되고 있음을 보여주었습니다. 이러한 벤치마크는 AI의 성능을 평가하고 실제 문제 해결 능력을 측정하기 위한 중요한 도구입니다. 이 포스팅에서는 o3 성능을 평가한 주요 벤치마크 테스트와 그 의미에 대해 알아보겠습니다.
글의 순서
SweetBench Verified
Codeforces
AMI (American Mathematics Invitational)
GPQA Diamond
Epic AI Frontier Math
Arc AGI
SweetBench Verified
SweetBench Verified는 현실 세계의 소프트웨어 작업으로 구성된 테스트입니다. 이는 AI가 코딩 작업을 얼마나 정확하게 수행할 수 있는지를 평가합니다. 이 테스트는 AI가 코딩 작업을 얼마나 정확하게 수행할 수 있는지 평가하며, 실제 프로그래밍 환경에서 문제 해결 능력을 측정합니다.
예를 들어, 계산기 앱처럼 숫자를 자동으로 계산하는 프로그램을 만들거나, 인터넷에서 날씨 데이터를 가져와 오늘의 날씨를 표시하는 기능을 구현할 수 있습니다. 또한, 컴퓨터에 저장된 사진과 문서를 날짜별로 정리하거나 중복된 파일을 삭제하는 프로그램도 포함됩니다. 쇼핑몰에서 장바구니에 담긴 상품에 자동으로 할인을 적용하거나, 인터넷 검색 결과를 요약해 보여주는 프로그램 역시 현실 세계의 소프트웨어 작업에 해당합니다.
이러한 작업들은 AI가 실제 코딩 환경에서 얼마나 유용하고 효과적으로 작동할 수 있는지를 평가하는 데 중요한 지표가 됩니다.
▶o3은 71.7%의 정확도를 기록하며, 이전 모델 O1보다 20% 이상 향상된 성능을 보여주었습니다.
Codeforces
Codeforces는 전 세계 프로그래머들이 경쟁 코딩 문제를 풀고 점수를 얻는 플랫폼입니다. 이 테스트에서는 AI의 코딩 실력을 사람과 동일한 기준으로 평가합니다. 예를 들어, 특정 도시에서 가장 빠른 경로를 계산하거나, 수백만 개의 데이터 중에서 특정 조건에 맞는 항목을 찾아내는 문제를 해결해야 합니다. 또 다른 예로, 게임에서 승리 확률을 계산하거나, 문자열 패턴을 분석해 특정 규칙에 맞는 결과를 도출하는 문제도 포함됩니다. Codeforces는 이러한 복잡한 알고리즘 문제를 AI가 얼마나 효율적으로 해결할 수 있는지를 보여줍니다.
▶o3은 2727 ELO(실력 점수)를 달성했으며, 이는 O1의 1891보다 월등히 높은 수치입니다.
여기서, ELO는 Elo Rating System에서 따온 용어로, AI의 상대적 실력을 수치로 표현하는 평가 시스템입니다. 원래 체스와 같은 1:1 경쟁 게임에서 사용되었지만, 현재는 다양한 분야에서 실력 점수를 평가하는 데 사용됩니다. 2727 ELO는 o3이 Codeforces 플랫폼에서 기록한 점수인데, 초보 프로그래머는 800~1000점, 중급 프로그래머는 1400~1800점, 고급 프로그래머는 2000점 이상의 수준으로 알려져 있습니다. 2700점 이상은 특급 프로그래머의 수준으로 볼 수 있습니다.
AMI (American Mathematics Invitational)
AMI는 미국 수학 올림피아드 예선을 의미하며, 고등학교 수학 천재들이 도전하는 시험입니다. 이 벤치마크는 AI가 복잡한 수학 문제를 풀어내는 능력을 평가합니다. 예를 들어, 피타고라스 정리를 활용해 삼각형의 한 변의 길이를 계산하거나, 복잡한 다항식을 인수분해하는 문제를 포함할 수 있습니다. 또한, 기하학 문제에서 각도와 길이를 계산하거나, 확률과 통계 문제에서 데이터 분포를 분석하는 작업도 평가 항목에 포함됩니다. AMI는 AI가 고도의 논리적 사고와 수학적 추론을 얼마나 잘 수행할 수 있는지를 보여줍니다.
▶o3은 96.7%의 정확도를 기록하며 O1(83.3%)을 크게 앞섰습니다.
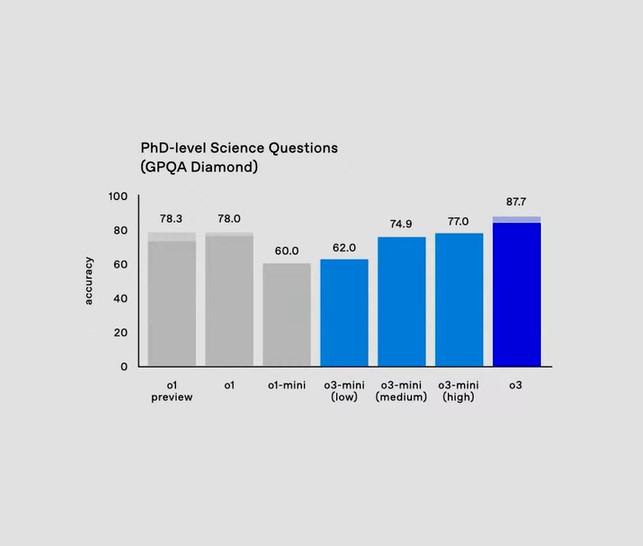
GPQA Diamond
GPQA Diamond는 박사 수준의 과학 질문에 AI가 얼마나 정확히 답할 수 있는지를 평가합니다. 예를 들어, 물리학에서는 양자역학의 개념을 활용해 입자의 운동을 설명하거나, 열역학 법칙에 기반해 에너지 변화를 계산하는 문제가 포함될 수 있습니다. 화학에서는 분자의 구조를 분석하거나 반응의 결과를 예측하는 질문이 나올 수 있으며, 생물학에서는 유전자 변형의 결과를 설명하거나 생태계의 상호작용을 분석하는 문제를 다룹니다. GPQA Diamond는 AI가 복잡한 과학적 지식을 얼마나 깊이 이해하고 정확히 활용할 수 있는지를 평가하는 중요한 척도입니다.
▶o3은 87.7%의 정확도를 기록하며, 인간 전문가(70%)보다 뛰어난 성과를 냈습니다.
Epic AI Frontier Math
Epic AI Frontier Math는 새롭고 발표되지 않은 문제들로 구성된, 현재 가장 어려운 수학적 벤치마크입니다. 예를 들어, 다중 변수의 관계를 분석해 새로운 방정식을 도출하거나, 기존의 수학 공식을 변형해 문제를 해결하는 작업이 포함될 수 있습니다. 또한, 정수론에서 고급 이론을 활용해 특정 숫자의 속성을 증명하거나, 그래프 이론을 적용해 네트워크 내 최단 경로를 계산하는 문제도 포함될 수 있습니다. Epic AI Frontier Math는 AI가 기존에 학습하지 않은 새로운 문제를 얼마나 창의적이고 효과적으로 해결할 수 있는지를 측정하는 데 초점을 맞춥니다.
▶기존 AI 모델의 평균 정확도는 2% 미만이었지만, o3은 25% 이상의 정확도를 기록했습니다.
Arc AGI
Arc AGI는 AI가 새로운 규칙을 학습하고 문제를 해결할 수 있는 능력을 평가합니다. AI가 주어진 입력 데이터를 기반으로 변환 규칙을 학습해 결과를 예측해야 합니다. 예를 들어, 주어진 패턴에서 색깔이나 모양의 규칙을 파악하고 다음에 올 모양을 예측하거나, 숫자 배열에서 특정 규칙을 찾아 다음 숫자를 계산하는 문제를 포함할 수 있습니다. 또한, 도형의 위치 변화를 분석해 움직임의 법칙을 추론하거나, 데이터를 통해 숨겨진 관계를 발견하는 작업도 평가 대상이 됩니다. Arc AGI는 AI가 기존에 학습하지 않은 상황에서 새로운 규칙을 스스로 이해하고 적용할 수 있는 능력을 측정합니다.
▶o3은 이 테스트에서 87.5점을 기록하며 인간의 평균 성능(85점)을 넘어섰습니다.
마치며 …
이번 포스팅에서는 2024년 12월 발표된 o3이 어떤 벤치마크 테스트를 거쳤는지, 그리고 이를 통해 o3의 능력이 어느 정도인지를 알아보았습니다.
o3은 SweetBench Verified와 Codeforces를 통해 프로그래밍에서 세계적인 수준의 실력을 증명했으며, AMI와 Epic AI Frontier Math 같은 테스트에서 뛰어난 수학적 추론 능력을 보여주었습니다. 또한, GPQA Diamond와 Arc AGI를 통해 과학적 사고와 새로운 규칙 학습 능력에서도 놀라운 성과를 기록했습니다.
이러한 벤치마크 결과는 o3이 단순히 데이터를 분석하는 도구를 넘어, 인간 수준의 복잡한 문제를 해결할 수 있는 AI로 진화하고 있음을 보여줍니다. 앞으로 o3은 코딩, 수학, 과학 등 다양한 분야에서 실제 문제를 해결하는 데 활용될 가능성이 높습니다. AI 기술의 진화가 어디까지 이어질지 기대되는 시점입니다. 이러한 기술의 발전을 어떻게 활용할 수 있을지 계속 관심 가져주시기 바랍니다.
함께 참고하면 좋은 글
▶ OpenAI o3 및 o3 mini
▶ o1-preview : GPT-4 이후 계속 발전하고 있는 AI 기술
▶ OpenAI o1-preview : GPT-4o와의 차이점, o1 시리즈 전망
▶ GPT-4o 발표, OpenAI의 시장 선점은 계속됩니다.
▶ 애플지능(Apple Intelligence), WWDC 2024에서 공개된 애플스런 AI
▶ 구글 I/O 2024. Gemini, 3분 요약 정리
▶ 구글 제미나이(GEMINI), 딥마인드가 만든 인공지능
참고자료
▶OpenAI(2024.13), o3 preview & call for safety researchers
▶OpenAI, OpenAI o3 and o3-mini – 12 Days of OpenAI: Day 12