파이썬 데이터 시각화 : 막대 그래프 작성 2가지 방법(maplotlib.pyplot 활용)
데이터를 받아서 분석할 때, 가장 먼저 하는 일이 데이터의 구조를 보는 것입니다. 데이터의 구조를 파악했다면, 그 다음 단계는 데이터 시각화입니다. 이번 포스팅 주제는 파이썬 데이터 시각화 도구 중 막대 그래프 작성 방법 2가지에 대한 것입니다. 1개의 그래프만 그릴 경우, 2개 이상의 그래프를 한 번에 그릴 경우로 구분해서 알아보겠습니다.
글의 순서
파이썬 데이터 분석 : 판다스 데이터프레임 활용
판다스 데이터프레임으로 데이터 파악하기
함수, 메쏘드, 어트리뷰트 구분
파이썬 데이터 시각화 : 막대 그래프(bar chart, matplotlib.pyplot 활용)
막대 그래프는 데이터의 크기를 막대 길이로 표현한 그림입니다. 데이터의 크기를 한 눈에 비교할 수 있다는 장점이 있습니다. 파이썬 matplotlib은 막대 그래프를 그리기 위한 bar() 함수를 제공합니다.
늘 그랬지만 가장 빨리 이해하는 것은 그냥 해보는 것입니다. matplotlib.pyplot으로 bar 차트를 그리는 2가지 방법을 정리해보겠습니다. 첫 번째는 하나의 막대 그래프를 단독으로 그리는 것이고, 두 번째는 여러 그래프를 한꺼번에 그리는 방법입니다. 막대 그래프로 그려볼 데이터는 아이폰15 프로맥스에 들어간 A17 Pro 칩부터, A13 Bionic 칩까지의 특징을 비교한 것입니다.
1개의 막대 그래프만 그릴 경우
파이썬 데이터 시각화를 위해 실습코드01에는 matplotlib 패키지에 있는 pyplot 모듈을 이용하여 1개의 그래프를 단독으로 그리는 방법을 나타내었습니다.
막대 그래프를 그리는 bar 함수는 가로축, 세로축에 들어갈 데이터를 인자로 받는데, 각각 가로축은 x, 세로축은 height입니다. 실습코드01에서 나온 bar 함수의 활용 방법은 아래의 단 1줄입니다. 실습코드01에는 x, height 이외에 alpha도 들어있는데, alpha는 투명도를 나타냅니다. alpha는 0부터 1 사이의 값으로, 0이면 완전투명, 1이면 완전불투명을 의미합니다.
plt.bar(x=df_sorted[‘model’], height=df_sorted[‘CPU_clock(GHz)’]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
import pandas as pd import matplotlib.pyplot as plt from matplotlib import font_manager, rc # 한글폰트 font_path = "C:/Windows/Fonts/malgun.TTF" font = font_manager.FontProperties(fname=font_path).get_name() rc('font', family=font) # 애플 A 시리즈 칩 데이터 data= { "model" : [ 'A17 Pro','A16 Bionic','A15 Bionic','A14 Bionic','A13 Bionic'], "date":['2023-09-12', '2022-09-07','2021-09-14','2020-09-15','2019-09-10'], "CPU_clock(GHz)":['3.78','3.46','3.23','3.1','2.65'], "process(nm)":['3','5','5','5','7'], "transistors(billion)":['19','16','15','11.8','8.5'] } # 01) 데이터프레임 생성 df = pd.DataFrame(data) print('\n','#01-1 df의 데이터 형태 파악') print(df) print('\n','#01-2 df의 열 속성: df.info()') print(df.info()) # 02) df의 데이터 타입 변경 df['date']=df['date'].astype('datetime64[ns]') df = df.astype({'CPU_clock(GHz)' : 'float', 'process(nm)' : 'float', 'transistors(billion)' : 'float'}) print('\n','#02 df의 데이터 타입 변경') print(df.dtypes) # 03) 날짜를 오름차순으로 정리 df_sorted = df.sort_values(by='date') print('\n','#03 날짜를 오름차순으로 정리') print(df_sorted) # 04) 파이썬 데이터 시각화 : 1개의 막대 그래프 # Bar plot plt.figure(figsize=(10,9)) plt.bar(x=df_sorted['model'], height=df_sorted['CPU_clock(GHz)'], alpha=0.7) plt.grid(True, axis='y', alpha=0.25) plt.xlabel('애플 실리콘 A 시리즈', fontsize=19) plt.ylabel('CPU clock rate(GHz)', fontsize=19) plt.xticks(fontsize=15) plt.tick_params(axis='x', rotation=15) plt.yticks(fontsize=15) plt.legend(fontsize = 15) plt.tight_layout(pad=2) plt.savefig(file_path +'apple_A_CPU-clock.png') plt.show() |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
#01-1 df의 데이터 형태 파악 model date CPU_clock(GHz) process(nm) transistors(billion) 0 A17 Pro 2023-09-12 3.78 3 19 1 A16 Bionic 2022-09-07 3.46 5 16 2 A15 Bionic 2021-09-14 3.23 5 15 3 A14 Bionic 2020-09-15 3.1 5 11.8 4 A13 Bionic 2019-09-10 2.65 7 8.5 #01-2 df의 열 속성: df.info() <class 'pandas.core.frame.DataFrame'> RangeIndex: 5 entries, 0 to 4 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 model 5 non-null object 1 date 5 non-null object 2 CPU_clock(GHz) 5 non-null object 3 process(nm) 5 non-null object 4 transistors(billion) 5 non-null object dtypes: object(5) memory usage: 328.0+ bytes None #02 df의 데이터 타입 변경 model object date datetime64[ns] CPU_clock(GHz) float64 process(nm) float64 transistors(billion) float64 dtype: object #03 날짜를 오름차순으로 정리 model date CPU_clock(GHz) process(nm) transistors(billion) 4 A13 Bionic 2019-09-10 2.65 7.0 8.5 3 A14 Bionic 2020-09-15 3.10 5.0 11.8 2 A15 Bionic 2021-09-14 3.23 5.0 15.0 1 A16 Bionic 2022-09-07 3.46 5.0 16.0 0 A17 Pro 2023-09-12 3.78 3.0 19.0 |
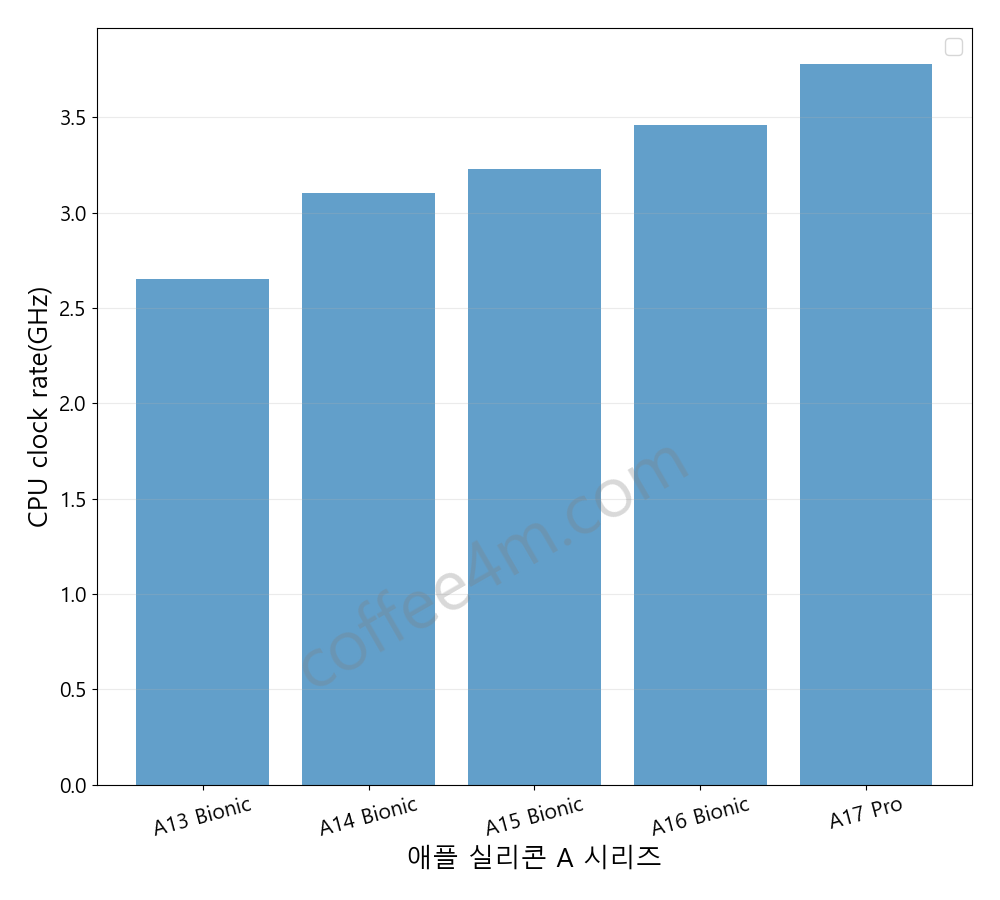
2개 이상의 막대 그래프를 그릴 경우 : subplots
matplotlib 패키지의 pyplot 모듈에는 여러 개의 그래프를 한 번에 그려주는 subplots이라는 함수가 있습니다. 파이썬 데이터 시각화를 위해 실습코드02에는 4개의 그래프를 그릴 수 있는 예제를 나타내었습니다. 실습코드02에서 여러 개의 그래프를 그리기 위한 핵심 구문은 다음과 같습니다.
fig, axs = plt.subplots(nrows=2, ncols=2, figsize=(10,9))
여기서는 fig, axs라는 순서가 중요합니다. fig, axs에 대한 자세한 사항은 아래의 함께 참고하면 좋은 글, 시계열 데이터 가시화 (4) 2개 y축 그래프로 코인 가격 비교
를 참조해 주시기 바랍니다.
4개의 그래프를 2행 2열(nrows=2, ncols=2)로 그리기 위해 2차원 배열로 axs를 잡았습니다. axs[ , ] 부분입니다. 만약 2개의 그래프를 2행으로만 또는 2열로만 그린다면 1차원 배열인 axs[ ] 형태가 됩니다. subplots으로도 1행, 1열, 그러니까 1개의 그래프를 그릴 수도 있는데, 이 경우 [ ]를 빼고 axs만 씁니다. 실습코드02 실행결과로 나온 그래프와 소스코드를 비교해보세요.
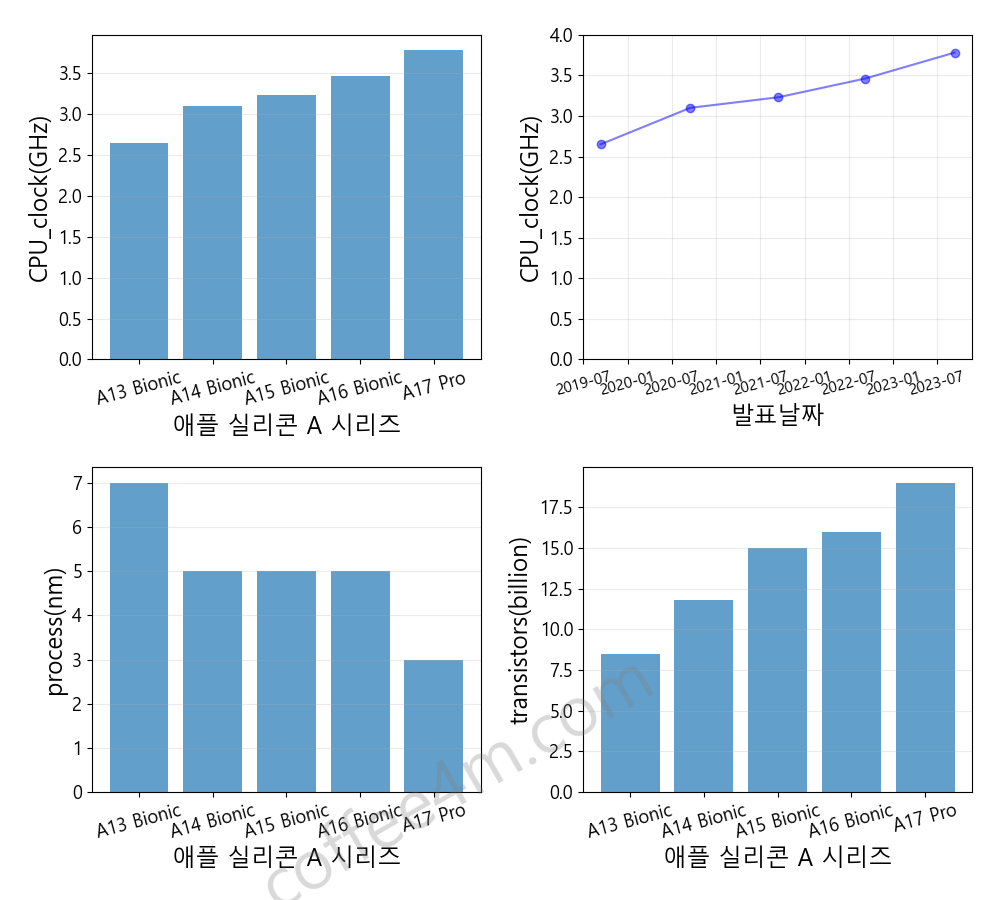
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
import pandas as pd import matplotlib.pyplot as plt from matplotlib import font_manager, rc font_path = "C:/Windows/Fonts/malgun.TTF" font = font_manager.FontProperties(fname=font_path).get_name() rc('font', family=font) # 애플 A 시리즈 칩 데이터 data= { "model" : [ 'A17 Pro','A16 Bionic','A15 Bionic','A14 Bionic','A13 Bionic'], "date":['2023-09-12', '2022-09-07','2021-09-14','2020-09-15','2019-09-10'], "CPU_clock(GHz)":['3.78','3.46','3.23','3.1','2.65'], "process(nm)":['3','5','5','5','7'], "transistors(billion)":['19','16','15','11.8','8.5'] } # 01) 데이터프레임 생성 df = pd.DataFrame(data) # 02) df의 데이터 타입 변경 df['date']=df['date'].astype('datetime64[ns]') df = df.astype({'CPU_clock(GHz)' : 'float', 'process(nm)' : 'float', 'transistors(billion)' : 'float'}) # 03) 날짜를 오름차순으로 정리 df_sorted = df.sort_values(by='date') # 04) 파이썬 데이터 시각화 : 2개 이상의 막대 그래프, subplots 이용 # Bar plot fig, axs = plt.subplots(nrows=2, ncols=2, figsize=(10,9)) axs[0,0].bar(x=df_sorted['model'], height=df_sorted['CPU_clock(GHz)'],alpha = 0.7) axs[0,0].grid(True, axis='y',alpha = 0.25) axs[0,0].set_xlabel('애플 실리콘 A 시리즈', fontsize=17) axs[0,0].set_ylabel('CPU_clock(GHz)', fontsize=17) axs[0,0].tick_params(axis='x', labelsize=13, rotation=15) axs[0,0].tick_params(axis='y', labelsize=13) axs[0,1].plot(df_sorted['date'], df_sorted['CPU_clock(GHz)'],'bo-',alpha = 0.5) axs[0,1].grid(True, alpha = 0.25) axs[0,1].set_xlabel('발표날짜', fontsize=17) axs[0,1].set_ylabel('CPU_clock(GHz)', fontsize=17) axs[0,1].set_ylim(0,4) axs[0,1].tick_params(axis='x', labelsize=11, rotation=15) axs[0,1].tick_params(axis='y', labelsize=13) axs[1,0].bar(x=df_sorted['model'], height=df_sorted['process(nm)'],alpha = 0.7) axs[1,0].grid(True, axis='y',alpha = 0.25) axs[1,0].set_xlabel('애플 실리콘 A 시리즈', fontsize=17) axs[1,0].set_ylabel('process(nm)', fontsize=17) axs[1,0].tick_params(axis='x', labelsize=13, rotation=15) axs[1,0].tick_params(axis='y', labelsize=13) axs[1,1].bar(x=df_sorted['model'], height=df_sorted['transistors(billion)'],alpha = 0.7) axs[1,1].grid(True, axis='y',alpha = 0.25) axs[1,1].set_xlabel('애플 실리콘 A 시리즈', fontsize=17) axs[1,1].set_ylabel('transistors(billion)', fontsize=17) axs[1,1].tick_params(axis='x', labelsize=13, rotation=15) axs[1,1].tick_params(axis='y', labelsize=13) plt.tight_layout(pad=2) plt.show() |
마치며 …
파이썬 데이터 분석의 첫 번째 단계는 데이터 구조 파악, 두 번째 단계는 데이터 시각화라고 할 수 있습니다. 이번 포스팅에서는 파이썬 데이터 시각화의 방법으로 막대 그래프에 대해 알아보았습니다.
1개의 막대 그래프를 단독으로 그리는 방법, 2개 이상의 막대 그래프를 한 번에 그리는 방법으로 구분하여 정리하였습니다. 파이썬 데이터 시각화를 위한 실습코드01, 실습코드02를 잘 저장해 두셨다가 유용하게 사용하시기 바랍니다.
함께 참고하면 좋은 글 :
▶ 파이썬 데이터 분석 : 판다스 인덱스
▶ 판다스 데이터프레임으로 빠르게 데이터 파악하기
▶ 파이썬 판다스로 엑셀 파일의 원하는 부분 골라 읽기
▶ 파이썬 판다스로 텍스트 파일 읽기 : read_table()
▶ 파이썬 판다스 데이터 분석 : pivot, 엑셀 입력, 출력
▶ 파이썬 바이낸스 API로 비트코인 투자 백테스팅 : 일중 강도(II) 매매 전략
▶ 파이썬 데이터 분석 : 판다스 데이터프레임 통계량, 그래프
▶ 시계열 데이터 가시화 (4) 2개 y축 그래프로 코인 가격 비교
참고자료
matplotlib, Matplotlib: Visualization with Python